
HTTP版本演进:第三回
本文的目的,就是要填前文留下的坑。为了更加充分的使用c端和s端的效率,解决队首阻塞。两个方案:并行tcp链接,以及http2.0版本的多路复用。
并行tcp链接
这个方法简单粗暴。1.1版本的http协议不是严格执行串行传输嘛,那好,我们就多开几个tcp链接。同时s端开启多线程并行处理响应。目前主流的浏览器厂商都默认最大支持6条线路。至于为什么是6,而不是更大的数值,权衡的结果。这种方法,能在一定程度上,实现优化的效果,但是治标不治本,对于并行的每条链路而言,依然存在队首阻塞的问题。
HTTP的2.0
HTTP/2基于SPDY,专注于性能,最大的一个目标是在用户和网站间只用一个连接(connection)
1. 二进制分帧
如下图所示: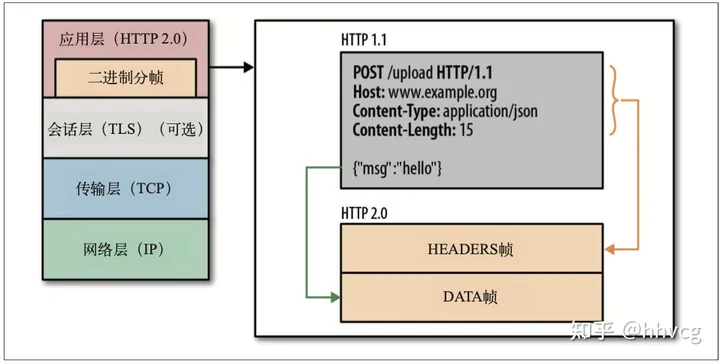
传统1.x传输的是纯文本的报文(字节), 而2.0是将请求和响应的数据切分成更小的数据帧,传输的是其二进制格式的数据,提高解析的效率。
2.0版本的数据传输如下图所示,所有的数据传输都是基于一个TCP链接。一个完整的请求响应称为一个流,流又有请求消息和响应消息组成,而具体的消息就是帧。这样的解释更多的是逻辑上的理解。本质就是数据被二进制分帧,乱序发送与组装,解决队首阻塞问题。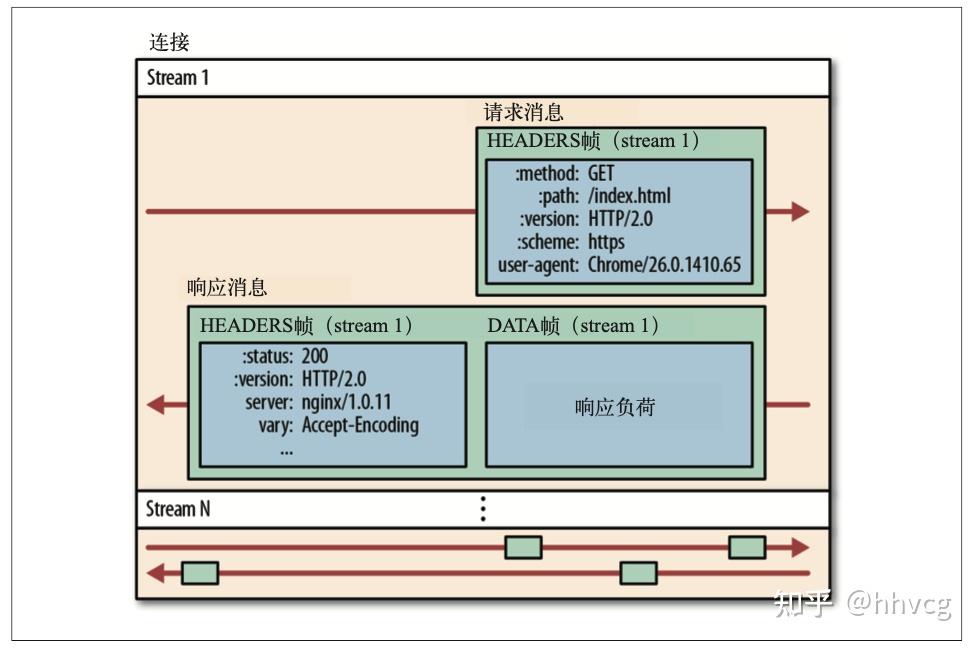
2. Header 压缩
HTTP/2并没有使用传统的压缩算法,而是开发了专门的”HPACK”算法,在客户端和服务器两端建立“字典”,用索引号表示重复的字符串,还采用哈夫曼编码来压缩整数和字符串,可以达到50%~90%的高压缩率。首个请求发送后,后面的请求中,只会发送与之前请求中不同的部分。
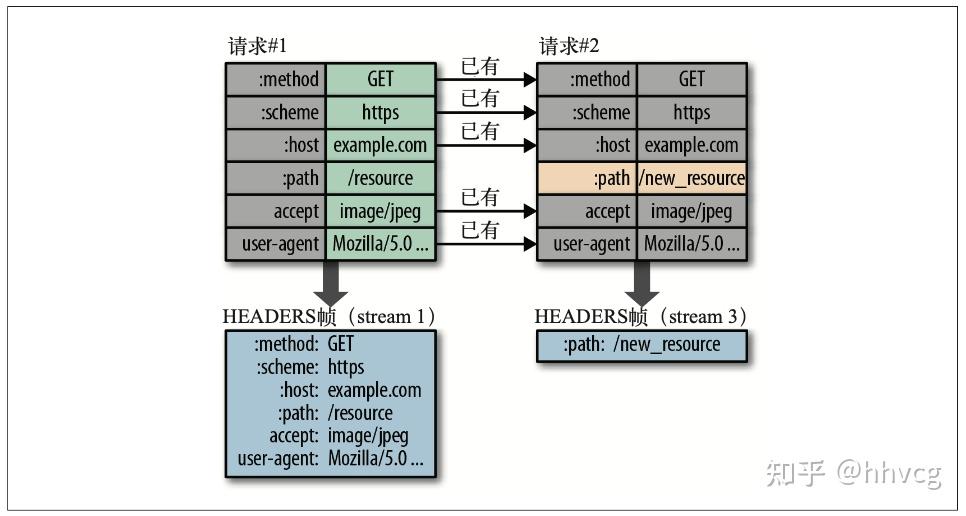 在2.0版本的机制中,c端和s端会维护自己的首部表来跟踪和存储之前发送的header中的键值对,对于相同的键值对,不会再发送。如上图所示,两个请求对比一下发现,除了请求路径不同,其他都没区别,因此发送的header帧中的信息,只有path字段及其对应的值。
在2.0版本的机制中,c端和s端会维护自己的首部表来跟踪和存储之前发送的header中的键值对,对于相同的键值对,不会再发送。如上图所示,两个请求对比一下发现,除了请求路径不同,其他都没区别,因此发送的header帧中的信息,只有path字段及其对应的值。
3. 请求优先级。
前端会发送很多请求,但并不是每个请求都同等重要。每个流都会带一个31比特的优先级值,0—2的31次方-1,从高到低。s端在准备好返回的数据时,会根据这个来决定返回顺序。
4. s端的“主动推送”
2.0之前的版本中,c端和s端的请求响应是一对一的关系,即:一个请求,对应一个响应。我们知道一个站点通常有很多资源构成,所以理所当然的想法,为什么不让s端主动推送一些可能是c端必须的资源而不是每次都等他发送请求呢?2.0针对这点做了改进。依然依附于请求-响应的循环,但是不是一对一,而是一对多,即:一个请求对应多个响应。那么具体是怎么实现的?是怎么个逻辑?
s端在发送响应之前,会主动发送一个PUSH_PROMISE帧信息,包含了s端想要主动推送的资源header,c端在收到这个帧信息后可以做取舍的决定,返回对应信息,最后由s端发送可能的多个响应。
在1.x版本中,我们其实可以通过内嵌地址的方式,让后段“主动”推送响应资源,但是这种推送响应更多的是“强制性”的,前端无法进行取舍。对了,顺带提一个首部字段X-Associated-Content 。如果后端是Apache搭建的话,就可以通过这个字段识别出前端希望主动推送的资源。
注意,一对多,有“一”才有后面的“多”,就是说,s端是不能在没有请求的情况下,向前端push资源的。还有一点是,2.0版本所做的改动,具体是由浏览器和服务器处理的,前端基本当着1.1版本用就行了。
总结一下就是:多路复用(取代并行TCP,解决队首堵塞问题),头部压缩(降低时间开销),s端的主动推送。当然还有一个很重要的点,二进制分帧层(核心)。2.0版本关注的重点,是如何让数据高效的在c端和s端进行传输,减小一切可能的延迟。
最后提一句:偶然间发现,chrome浏览器貌似都不显示http版本号了,火狐可以。且目前,2.0版本已经得到了普及。