
Webkit系列:第二回(HTML解释器和DOM模型)
本文将尽可能的解释Webkit的HTML解释器流程及Dom模型相关的知识点
在前文介绍从输入url到页面的最终呈现的过程,其中有一步:渲染器进程获取到资源后会将html资源给到html解释器,用来生成dom节点最终生成dom树形结构的对象。那么html解释器具体做了啥呢?
总体流程:字节流被解码成字符流,字符流通过词法分析器被解释成词语,词语通过语法分析器构建成节点,最后节点组合成dom树。
1. 字节 —> 字符
收到字节流之后,解释器会根据网页内容所使用的编码格式,将字节流解析成对应的字符串。如果没有特别指定编码格式,直接进入下一步的词法分析。
2. 字符 —> 词语HTMLTokenizer
HTMLTokenizer类负责词法解析。输入字符串,输出是一个个的词语。
解释完成的词语会经过XSSAuditor安全验证,干嘛的呢?实质就是将一些可能会导致安全问题的词语过滤掉。只有通过安全验证的词语,才会继续下一步。
3. 词语 —> 节点HTMLTreebuilder类的construcTree
由词语创建节点过程中,坑会遇到js代码。这就是为什么全局执行的js无法访问dom,因为此时dom还没建完。且此时执行js甚至还要通过src下载js脚本时,会使得dom树构建停止。
所以建议js的代码,要么异步async,要么塞在body结束标签的下面。
4. 众多节点 —> dom树
dom模型的事件机制
无非就是捕获与冒泡。addEventListener这个api的第三个参数需要注意。默认为false也就是冒泡,设置为true时就走的捕获。
渲染引擎接收到一个事件时,会通过HitTest来检查,具体是哪一个元素触发的。然后根据相关参数确定事件触发流向。能准确说出下面代码的输出,基本就理解了。
// 事件捕获冒泡
const body = document.getElementById('body')
body.addEventListener('click', (event) => {
console.log('body')
})
const div = document.getElementById('div')
div.addEventListener('click', (event) => {
console.log('div')
}, true)
const img = document.getElementById('img')
img.addEventListener('click', (event) => {
console.log('img')
event.stopPropagation()
})shadow-dom
所谓shadow-dom就是影子dom,说白了就是对一些元素进行了封装。
拿video标签举例解释。
当我们在页面中使用了一个video标签,它自动的给我们一个如上图所示的播放器,包括进度条、音量控制、全屏按钮等小的组件但是,dom结构层面确实只有一个叫video的元素。如何做到的?
shadow-dom。video标签的内部,实际也是一坨div组成的代码,只不过内部做了层封装。
实机演示:
window.onload = function() {
const div = document.getElementById('div')
console.log('div>>>', div)
// const root = div.webkitCreateShadowRoot()
const root = div.attachShadow({ mode: 'open' });
// const root = div.createShadowRoot()
const img = document.createElement('img')
img.width = '100'
img.height = '100'
img.src = './bigPic.png'
root.appendChild(img)
const shadowDiv = document.createElement('div')
shadowDiv.innerHTML = 'this is shadow'
root.appendChild(shadowDiv)
}打开控制台查看发现: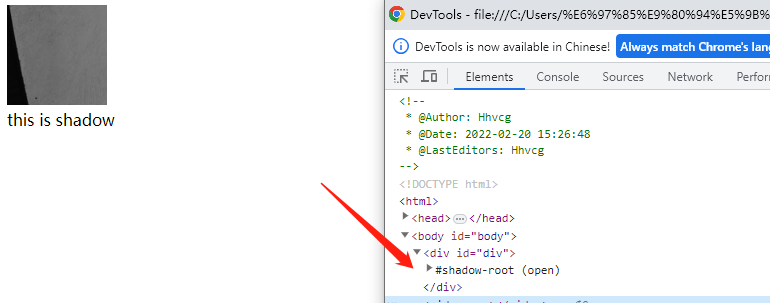
div内部并没有img等子元素,反而是一个叫#shadow-root的东西,这就是那一层封装。
完毕。